副档联动处理器的设计与封装
在单据系统里,副档通常就是明细行。以进销存、ERP 场景为例,一行明细里会有产品、批号、数量、单位、单价、金额、仓库等字段。这些字段不是孤立存在的:选择产品后要带出品名、规格、默认单位;改数量或单位后要重算基本单位数量;单价、数量、金额之间还存在正算和反推;有些单据还要根据产品带出仓库、库存、抵扣率等业务字段。
这类联动如果直接写在接口里,很容易变成一串很长的 if。更麻烦的是,字段之间会互相影响:用户改了产品,系统派生出单位;单位变化又影响数量换算;数量变化又影响金额。若没有清晰的边界,代码会把「用户主动修改」和「系统派生修改」混在一起,最终变成顺序敏感、难以复盘、甚至可能循环触发的逻辑。
BaseBusinessAssistantLinkageHandler 这套封装的核心目标就是把这件事拆开:用工厂 + 策略选择不同作业项处理器,用模板方法固定处理流程,用上下文保存本次联动的语义,用钩子函数开放扩展点,用一次结算保证公共字段稳定自洽。
整体调用关系
从一次副档联动请求看,整体链路大致是:
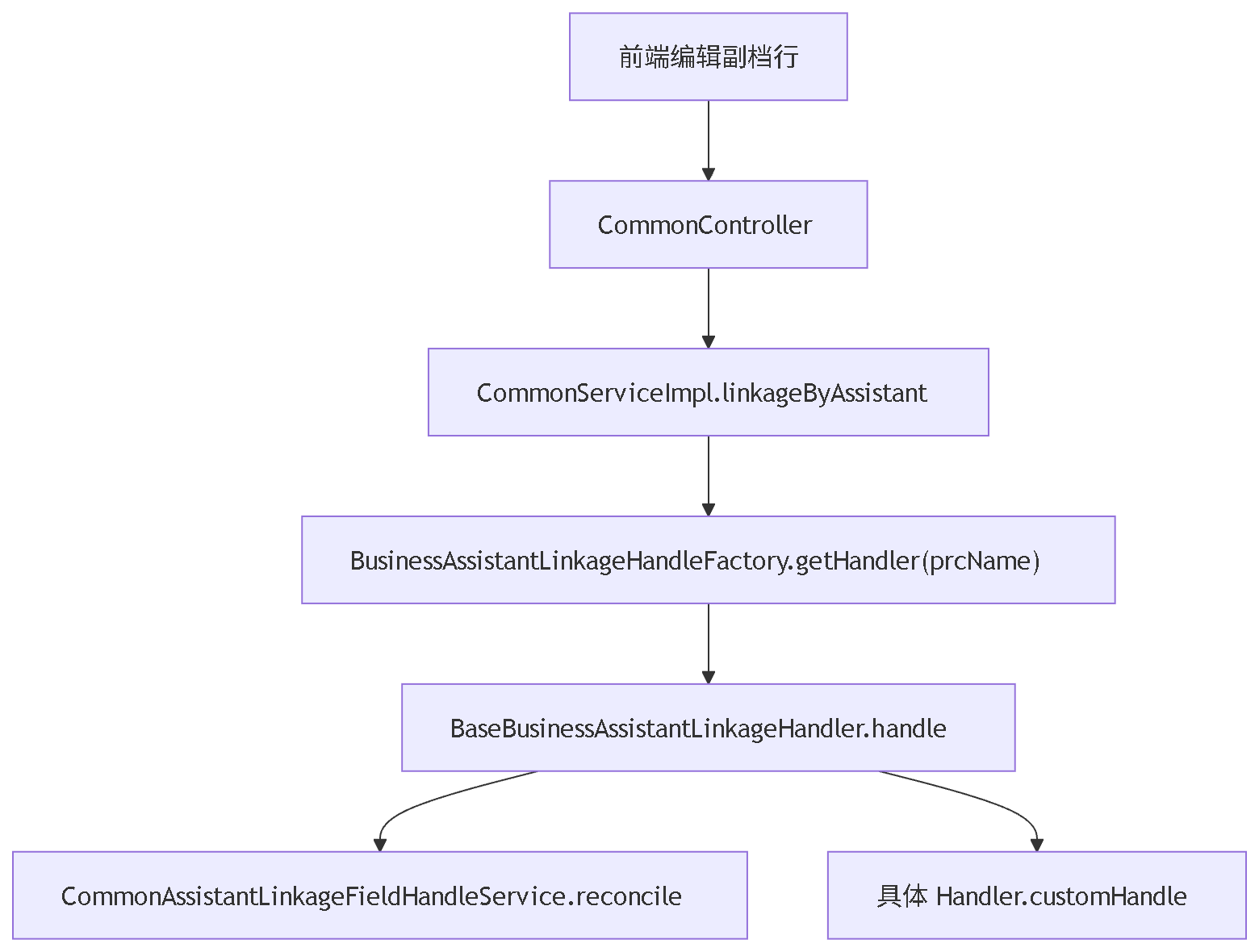
CommonServiceImpl 不关心具体是哪一种单据,只根据 prcName(模块名) 从工厂取一个处理器,然后把每一行副档交给处理器:
BaseBusinessAssistantLinkageHandler<?> handler =
BusinessAssistantLinkageHandleFactory.getHandler(param.getPrcName());
return param.getAssistantItems()
.stream()
.map(assistantItem ->
handler.handle(assistantItem.getAssistantItemObject(), assistantItem.getChangeFields()))
.toList();这里已经体现了第一层抽象:入口服务只做分发,不承载具体业务联动。具体规则被延迟到 Handler 中处理。
为什么使用工厂 + 策略模式
副档联动的第一个变化点是「不同作业项有不同逻辑」。例如默认副档只需要通用字段联动,而其它入库单可能还要处理仓库、现存量、抵扣率等字段。如果用 if/else 或 switch 写在一个服务里,作业项越多,中心类就越臃肿。
所以这里把每个作业项看作一个策略:
@BusinessAssistantLinkageHandler(prcName = "STKOTHERIN")
public class StkotherinAssistantLinkageHandler
extends BaseBusinessAssistantLinkageHandler<BizStkotherinAssistantLinkageEntity> {
// ...
}工厂在启动时扫描所有 BaseBusinessAssistantLinkageHandler 类型的 Bean,根据注解上的 prcName(模块名) 注册到 Map:
private static final Map<String, BaseBusinessAssistantLinkageHandler<?>> HANDLER_MAP =
new ConcurrentHashMap<>();
@PostConstruct
public void init() {
Map<String, BaseBusinessAssistantLinkageHandler> beansOfType =
SpringUtil.getBeansOfType(BaseBusinessAssistantLinkageHandler.class);
for (BaseBusinessAssistantLinkageHandler<?> handler : beansOfType.values()) {
Class<?> userClass = ClassUtils.getUserClass(handler);
BusinessAssistantLinkageHandler annotation =
userClass.getAnnotation(BusinessAssistantLinkageHandler.class);
if (annotation != null) {
HANDLER_MAP.put(annotation.prcName(), handler);
}
}
}运行时只需要按 prcName(模块名) 获取策略:
public static BaseBusinessAssistantLinkageHandler<?> getHandler(String prcName) {
BaseBusinessAssistantLinkageHandler<?> handler = HANDLER_MAP.get(prcName);
if (handler != null) {
return handler;
}
return HANDLER_MAP.get(BusinessCommonConstant.DEFAULT_ASSISTANT_LINKAGE_HANDLER_NAME);
}这样设计的好处是:作业项逻辑和入口服务解耦,中心流程保持稳定;新增一个作业项,本质上只是新增一个策略实现;默认处理器也能兜底通用场景。
为什么使用模板方法固定流程
第二个变化点是「每个作业项都有差异,但处理步骤又高度相似」。一行副档进入系统后,大体都要经历这些步骤:
- 创建对应的实体对象;
- 把入参拷贝到实体;
- 根据变更字段初始化上下文;
- 先处理公共字段联动;
- 再处理作业项自定义字段联动;
- 返回最终实体。
这些步骤不应该每个 Handler 都复制一遍,所以基类用模板方法固定主流程:
public BaseBusinessAssistantLinkageEntity handle(Object assistantObject, List<String> changeFields) {
BaseBusinessAssistantLinkageEntity param = createdEntity();
BeanUtil.copyProperties(assistantObject, param);
if (changeFields.isEmpty()) {
return param;
}
AssistantLinkageContext context = initContext(param, changeFields);
commonHandle(context, param);
return customHandle(context, (T) param);
}其中 createdEntity 和 customHandle 由子类实现:
protected abstract BaseBusinessAssistantLinkageEntity createdEntity();
protected abstract BaseBusinessAssistantLinkageEntity customHandle(
AssistantLinkageContext context,
T entity);模板方法的价值在于:流程顺序由基类统一控制,业务差异通过抽象方法和钩子函数注入。这样既避免重复代码,也减少不同作业项各写各的导致顺序不一致。
为什么加入上下文机制
字段联动里最容易混淆的是两件事:
- 用户这次到底改了哪些字段;
- 系统在联动过程中又派生影响了哪些字段。
如果只用一个 changeFields 集合,用户改动和派生改动就会混在一起。比如用户改了产品,系统顺带带出了仓库。如果后续逻辑无法区分「用户主动改仓库」还是「产品联动带出仓库」,钩子的语义就会变得不稳定。
因此这里引入 AssistantLinkageContext,明确拆成两套集合:
public class AssistantLinkageContext {
private Product product;
private final Set<String> userChangedFields;
private final Set<String> dirtyFields;
public AssistantLinkageContext(Collection<String> changeFields) {
this.userChangedFields = new LinkedHashSet<>(changeFields);
this.dirtyFields = new LinkedHashSet<>(this.userChangedFields);
}
public boolean isUserChanged(String fieldName) {
return userChangedFields.contains(fieldName);
}
public boolean isChangeField(String fieldName) {
return dirtyFields.contains(fieldName);
}
public boolean addChangeField(String fieldName) {
return dirtyFields.add(fieldName);
}
}这里的关键是两种语义:
| 方法 | 语义 | 使用位置 |
|---|---|---|
isUserChanged(field) | 字段是否来自本次请求的用户编辑 | 公共结算入口判断、决定是否触发钩子 |
isChangeField(field) | 字段是否在本次链路中发生过变化,包含用户编辑和派生变化 | 自定义处理里继续消费派生结果 |
addChangeField(field) | 标记一个字段被联动派生影响 | 钩子或自定义逻辑中记录后续处理依据 |
上下文里还可以放本次联动过程共享的数据,例如产品信息。基类初始化上下文时,如果副档里有产品代码,就先查产品并放入上下文:
private AssistantLinkageContext initContext(BaseBusinessAssistantLinkageEntity param,
List<String> changeFields) {
AssistantLinkageContext context = new AssistantLinkageContext(changeFields);
if (StrUtil.isNotEmpty(param.getProd())) {
ProductService productService = SpringUtil.getBean(ProductService.class);
Product product = Optional
.ofNullable(productService.queryByProductCode(param.getProd()))
.orElseThrow(() -> new CommonException("未查询到产品代码对应产品信息"));
context.setProduct(product);
}
return context;
}所以 context 不只是一个参数对象,它承担了本次联动的「语义载体」角色:保存用户意图、派生痕迹和共享查询结果。
为什么使用钩子函数
公共字段联动完成后,某些作业项还需要对特定用户动作做扩展。例如用户改了产品,通用逻辑会带出产品名称、规格、单位等;但某个作业项还希望同时带出默认仓库和抵扣率。
这类逻辑不能写死在公共服务里,否则公共服务会被各种单据的细节污染。于是基类提供一组空实现钩子:
protected void onProdFieldUpdated(AssistantLinkageContext context, T entity) {
}
protected void onQtyFieldUpdated(AssistantLinkageContext context, T entity) {
}
protected void onAmountFieldUpdated(AssistantLinkageContext context, T entity) {
}基类在 commonHandle 中只在「用户真正改了这个字段」时触发对应钩子:
private void commonHandle(AssistantLinkageContext context,
BaseBusinessAssistantLinkageEntity entity) {
CommonAssistantLinkageFieldHandleService handleService =
SpringUtil.getBean(CommonAssistantLinkageFieldHandleService.class);
handleService.reconcile(context, entity);
if (context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_PROD)) {
onProdFieldUpdated(context, (T) entity);
}
if (context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_QTY)) {
onQtyFieldUpdated(context, (T) entity);
}
if (context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_AMOUNT)) {
onAmountFieldUpdated(context, (T) entity);
}
}钩子的核心不是“字段变了就调”,而是“用户主动改了这个字段才调”。这样语义会非常清晰:onProdFieldUpdated 表达的是对用户选品动作的响应,而不是对任意产品字段变化的响应。
具体子类可以只覆盖关心的钩子:
@Override
protected void onProdFieldUpdated(AssistantLinkageContext context,
BizStkotherinAssistantLinkageEntity entity) {
Product product = context.getProduct();
entity.setGwn(product.getGodowncode());
context.addChangeField(StkotherinAssistantLinkageField.GWN);
entity.setDeductionRate(BigDecimal.ZERO);
context.addChangeField(StkotherinAssistantLinkageField.DEDUCTION_RATE);
}这个例子里,产品变化带出了仓库和抵扣率。注意它没有把这些派生字段加入 userChangedFields,而是加入 dirtyFields。这正是上下文机制和钩子函数配合的地方:用户意图不被污染,派生影响仍可继续向后传递。
为什么公共字段使用“一次结算”
公共字段之间有强依赖关系,如果通过 addChangeField 一个字段驱动另一个字段,会产生两个问题:
- 执行顺序很隐蔽,读代码时要追着字段标记来回跳;
- 派生字段继续触发派生字段,容易遗漏边界,甚至形成循环。
所以公共字段没有继续走「字段互相驱动」模式,而是集中到 CommonAssistantLinkageFieldHandleService.reconcile 里按固定阶段一次算完:
public void reconcile(AssistantLinkageContext context,
BaseBusinessAssistantLinkageEntity entity) {
if (context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_PROD)) {
verifyFieldNotNull(entity.getProd(), BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_PROD);
applyProductSelection(context, entity);
}
if (context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_VP_NO)) {
verifyFieldNotNull(entity.getVpNo(), BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_VP_NO);
}
if (StrUtil.isNotEmpty(entity.getVpNo())) {
applyVpNo(context, entity);
}
fillUnitName(entity);
recalcNumberOfBasicUnit(context, entity);
applyOtherUnit(context, entity);
recalcOuqty(context, entity);
if (isAmountAnchored(context)) {
recalcPriceFromAmount(entity);
} else {
recalcAmount(entity);
}
}这个顺序本身就是业务规则的表达:
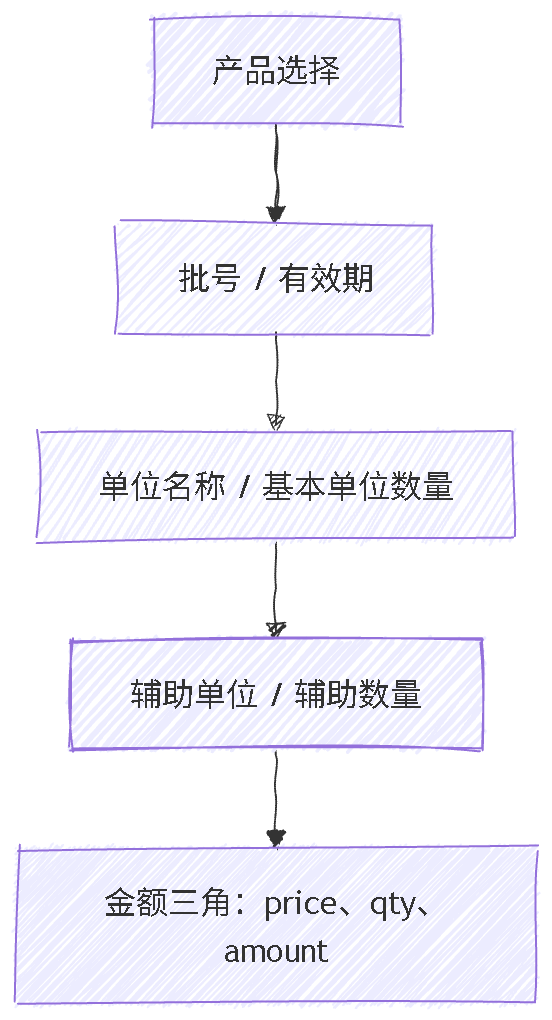
金额部分额外有一个锚点规则:如果用户只改了金额,且没有同时改产品、单位、数量、单价,那么认为金额是用户想保留的值,反推单价;否则按单价乘基本单位数量正算金额。
private boolean isAmountAnchored(AssistantLinkageContext context) {
return context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_AMOUNT)
&& !context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_PRICE)
&& !context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_QTY)
&& !context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_UNIT)
&& !context.isUserChanged(BusinessCommonConstant.COMMON_ASSISTANT_LINKAGE_FIELD_PROD);
}这也是「用户意图」为何必须单独保存的原因:如果金额只是系统派生出来的 dirty 字段,就不能把它当作用户锚定金额。
自定义逻辑如何继续消费 dirty 字段
钩子适合处理“用户改某个公共字段时,顺便派生作业项字段”。而 customHandle 更像是最后的业务收口:它可以根据上下文里的 dirty 字段继续完成扩展字段的查询和计算。
例如其它入库单中,产品变动钩子会把 GWN 和 DEDUCTION_RATE 标记为 dirty,随后 customHandle 根据 dirty 继续处理:
@Override
protected BaseBusinessAssistantLinkageEntity customHandle(
AssistantLinkageContext context,
BizStkotherinAssistantLinkageEntity entity) {
if (context.isChangeField(StkotherinAssistantLinkageField.GWN)) {
String godownCode = verifyFieldNotNull(entity.getGwn(), StkotherinAssistantLinkageField.GWN);
Optional.ofNullable(godownService.queryByCode(godownCode))
.ifPresent(godown -> entity.setGwnName(godown.getName()));
BigDecimal inventory = prodqtyService.queryInventoryOnHandByProductCodeAndRepositoryCode(
entity.getProd(),
entity.getGwn());
entity.setInventoryOnHand(inventory);
}
if (context.isChangeField(StkotherinAssistantLinkageField.DEDUCTION_RATE)) {
BigDecimal qty = Optional.ofNullable(entity.getQty()).orElse(BigDecimal.ONE);
entity.setDeductionAmount(entity.getDeductionRate().multiply(qty));
}
return entity;
}这里的分层比较清楚:
reconcile处理所有副档通用字段;onProdFieldUpdated响应用户选品动作,派生出作业项字段;customHandle根据 dirty 字段继续做查询、名称回填、业务计算。
泛型在这里解决什么
基类声明如下:
public abstract class BaseBusinessAssistantLinkageHandler<T extends BaseBusinessAssistantLinkageEntity>公共字段都在 BaseBusinessAssistantLinkageEntity 上,但具体作业项会有自己的扩展字段,例如 BizStkotherinAssistantLinkageEntity。如果不用泛型,子类每次访问扩展字段都需要手动强转;如果把基类写死成某个具体实体,又失去了抽象能力。
因此这里让子类指定自己的实体类型:
public class StkotherinAssistantLinkageHandler
extends BaseBusinessAssistantLinkageHandler<BizStkotherinAssistantLinkageEntity> {
@Override
protected BaseBusinessAssistantLinkageEntity createdEntity() {
return new BizStkotherinAssistantLinkageEntity();
}
@Override
protected BaseBusinessAssistantLinkageEntity customHandle(
AssistantLinkageContext context,
BizStkotherinAssistantLinkageEntity entity) {
// 这里可以直接访问 BizStkotherinAssistantLinkageEntity 的扩展字段
return entity;
}
}对外,工厂统一保存为 BaseBusinessAssistantLinkageHandler<?>,因为调用侧并不关心具体泛型,只需要调用统一的 handle:
BaseBusinessAssistantLinkageHandler<?> handler =
BusinessAssistantLinkageHandleFactory.getHandler(prcName);这就是这套泛型边界的取舍:内部让子类拿到强类型实体,对外用通配符屏蔽差异。
单次处理流程复盘
把前面的点合在一起,一次 handle 的内部处理关系可以这样理解:
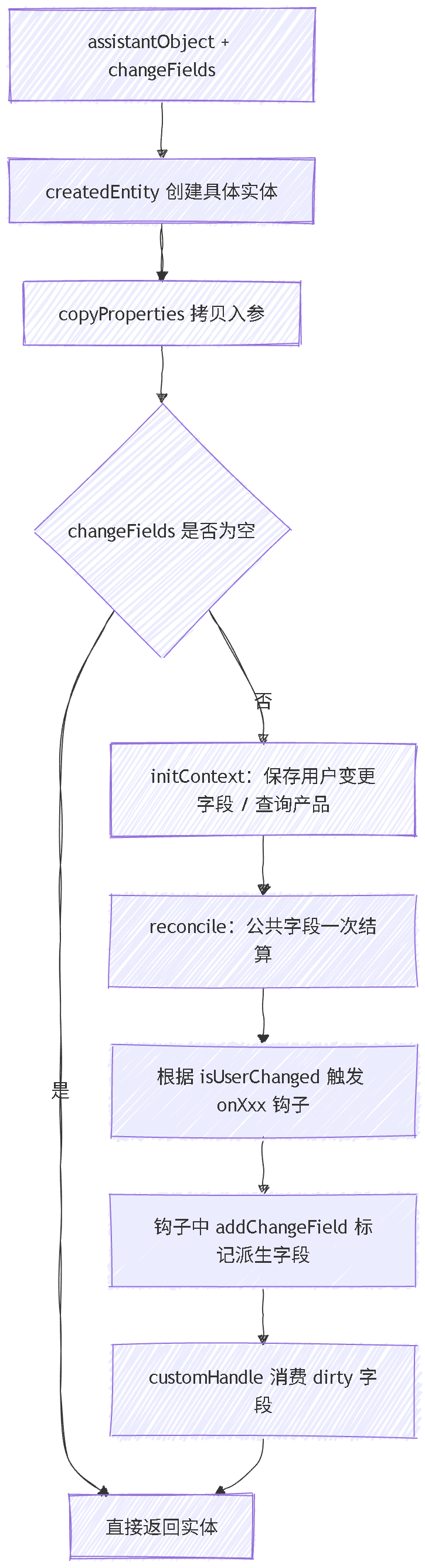
这套封装最关键的不是用了多少设计模式,而是把几个容易混在一起的概念拆开了:
- 用工厂 + 策略解决「按作业项选择实现」;
- 用模板方法解决「流程稳定、差异可插入」;
- 用上下文解决「用户变更和派生变更的语义区分」;
- 用钩子函数解决「公共动作触发业务扩展」;
- 用一次结算解决「公共字段依赖顺序和循环风险」。
回头看这套设计时,只要抓住这几个分界点,就能快速理解为什么副档联动没有被写成一坨业务 if。